
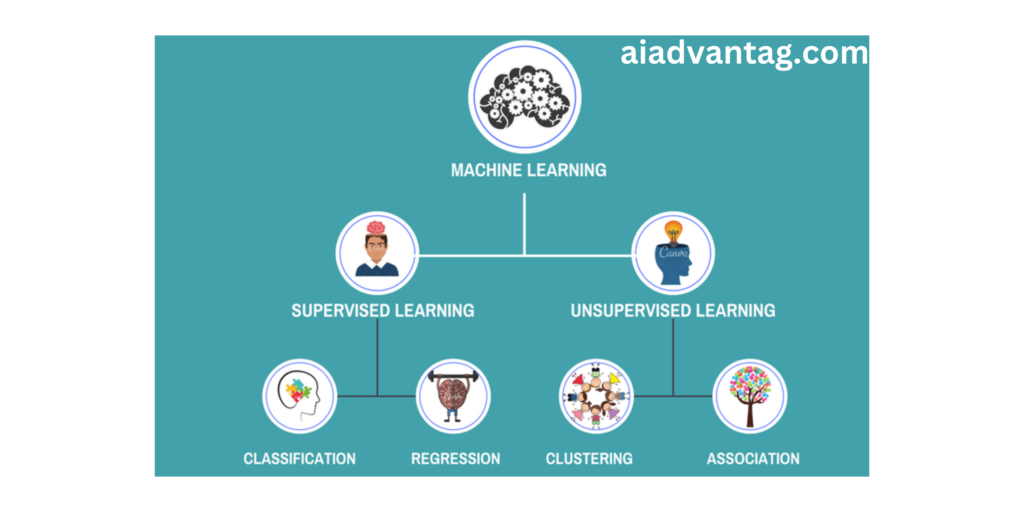
Supervised Learning strategies – regression versus classification:
Unsupervised and Classification algorithms are supervised learning algorithms. Both of these algorithms are used to predict machine leaming and work with label datasets, But he difference between the two is how they are applied to various machine learning problems.
The main difference between Regression and Classification algorithms is that Classification algorithm is used to predict the discrete values such as Male or Female, True or False, Spam or Not Spam, etc. whereas Regression algorithm is used to predict continuous values such as price, salary, age, etc. Spam or Not Spam, etc.
Classification:
Classification is the process of finding a function that helps to classify the database into categories based on different parameters.
In classification, a computer program is trained in a training database and based on that training, classifies data into different categories. The function of the segmentation algorithm is to find a map function to map input (x) of different output (y).
Example: A good example of understanding the problem of separation is the detection of spam email. The model is trained on the basis of millions of emails in different parameters, and whenever it receives a new email, it indicates whether the email is spam or not. If the email is spam, it is then moved to the spam folder.
Types of Machine Learning Classification Algorithms
- Logistic Regression
- K-Nearest Neighbours
- Support Vector Machines
- Naive Bayes
- Kermel SVM
- Decision Tree Classification
Regression:
Top casts, etc. The function of the Regression algorithm is to find the map function to turn the input variable (x) of the continuous output variable (y)
Example: Suppose we want to predict the weather, so in this case, we will use the Regression algorithm. In weather forecasting. the model is trained in past data. and once the training is completed, it can easily predict future weather.
Types of Regression Algorithm:
- ✔ Simple Linear Regression
- ✔ Multiple Linear Regression
- Polynomial Regression
- ✔ Support Vector Regression
- ✔ Decision Tree Regression
- ✔ Random Forest Regression
Unsupervised problem solving-clustering –
When faced with real-world problems, most of the time, data will not come wait predefined labels, so we will want to develop machine learning models that can better differentiate this data, by discovering for themselves some common features, which will be used to predict classes in new data.
The purpose of the merger is to find different groups within the data elements. To do so, integration algorithms detect data formation so that objects of the same group (or group) are more similar than those from different collections.
Many non-invasive problem solving involves collecting objects by looking at the similarity or number of shared features of the visuals, because there is no specific information about the priori categories. This type of strategy is called integration.
Apart from these main types of problems, there is a combination of both, called problem- solving problems, in which we can train a set of label items and use an index to provide information on non-label information during training.
Distributing data to anonymous organizations, using three main methods – slide (points close to each other belong to the same category), group (data often form clusters, special slip case).
Types of machine learning:
Machine learning is a concept that allows the machine to learn from examples and experiences, and that too without being organized. So instead of coding. what you do is feed the data into a standard algorithm, and the algorithm /machine creates an idea based on the data provided.
Let see application of machine learning in or real life:
Ever bought online? So while reviewing a product, are you careful when recommending a product that matches what you want? or note that the person who purchased the product also purchased this product combination. How do they make this recommendation? This is machine learning.
Machine learning is a set of artificial intelligence that focuses on machine learning from knowledge and making predictions based on their experience. It empowers numbers or devices to make data-driven decisions rather than explicitly planning to m a specific task. These programs or algorithms are designed in a way that learns and develops over time as they are exposed to new data.
Machine Learning algorithm is trained in setting up training data to create a model. When New input details are introduced in the ML algorithm, it makes predictions based on the model. Predictions are tested for accuracy and if accuracy is accepted, the Learning Machine algorithm is included.
If accuracy is not acceptable, the Learning Machine algorithm is repeatedly trained with augmented data set. There are many ways to frame this idea, but in particular there are three major categories known.
Supervised Learning:
Supervised Learning, where you might think the learning is guided by a teacher. We have a dataset that works as a teacher and its role is to train a model or machine. When a training model can begin to make predictions or decisions when given new data.
For Example: teaching alphabets to child using finish cards. Which consist of both image and Even the data in the form of label examples, we can feed the algorithm for reading sample label pairs individually, allow the algorithm to predict the label for each Sample, and give it feedback on whether it predicts the correct answer or not. Over time, e algorithm will learn to measure the exact nature of the relationship between models and their labels.
When fully trained, the supervised learning algorithm will be able to detect new, unprecedented patterns and predict its own good label. Supervised learning is often described as work-directed as a result.
It focuses on the work of unity, finding more and more examples in the algorithm until it can perform more accurately in that task. This is the kind of reading you will most likely encounter, as Advertising Preferences: Selecting ads that will work best is usually a learning task.
Most Said they were very popular (and clickable). Additionally, its placement is associated with a specific site or query (if you find yourself using a search engine) mainly because of an educated algorithm that says similarities between ad and placement will work.
Spam Separation: If you are using a modern email program, you may have encountered a spam filter. This spam filter is a curated reading program.
Examples of emails and labels (spam / not spam), these programs learn how to pre-filter bad emails so that their user is not harassed by them. Many of these also behave in such a way that the user can provide new labels to the system and can read user preferences.
Face Recognition: Have you used Facebook? Your face may be used in a supervised reading algorithm trained to detect your face. Having a photo-taking, face-to-face program, and guessing who is in the picture (raising the marker) is a supervised process. It has a lot of layers on it, it finds faces and points at them, but it’s still being watched anyway.
Unsupervised Learning:
The model learns by observing and discovering properties in data. When a model is given a database, it automatically detects patterns and relationships in the database by creating clusters in it.
What he can do is put labels in the collection, as it does not mean that this is a group of apples or mangoes, but it will separate all apples from mangoes.
Suppose we present pictures of apples, bananas and mangoes in the model, so what it does, based on other patterns and relationships build clusters and separate the databases from those collections. Now when new data is added to the model, it adds it to one of the created collections.
Unsupervised learning is very different from supervised learning. No labels. Instead, our algorithm will be fed with a lot of detail and provided with tools to understand data structures.
From there, it can learn to collect, compile, and / or organize data in such a way that a person (or other intelligent algorithm) can enter and make sense of newly credit data.
For example, what if we had a large database of all the research papers that have already been published and we had surveyed study programs that knew how to collect them in such a way that you were always aware oft current trends within a particular research domain.
Now, you start your own research project, connecting your work to this network hat you can See the algorithm. As you write your work and take notes, the algorithm hakes suggestions for you about related tasks, tasks you would like to mention, and it works that can help you move forward in that research area. With such a tool, your product can be maximized.
se unsupervised learning is based on data and its properties, we can say that hack reading is driven by data. Outcomes from unsupervised learning activity are trolled by data and formatted. Some areas where you can see that unsupervised reading restrictions are.

Recommendation Programs:
If you have ever used YouTube or Netflix, you may have encountered a video recommendations program. These applications are usually installed on an unmanaged domain. We know things about videos, maybe their length, genre, etc.
We also know the watch history of multiple users. Considering users who have watched similar videos like you and enjoyed other videos you have not yet seen, the recommendation system can detect this data relationship and provide you with such a suggestion.
Purchasing Practices:
It is possible that your purchase practices are contained in the database elsewhere and that the data is actively purchased and sold at this time.
These purchase practices can be applied to learning algorithms that can be controlled to gather customers in the same shopping categories. This helps companies market in these aggregated categories and can serve as promotional programs.
Which types of Machine Learning ?
Logistic Regression
K-Nearest Neighbours
Support Vector Machines
Naive Bayes
Kermel SVM
Decision Tree Classification
User Logging:
A little user experience, but still very effective, we can use unchecked reading to collect logs and user problems. This can help companies identify key themes in the problems their customers face and address these issues, by improving product or designing FAQ to address common issues. In any case.
It is a work in progress and if you have ever caused a problem with a product or submitted a bug report, it may have been feed an unattended reading algorithm to integrate it with other similar issues.
Reinforcement:
It is the agent’s ability to interact with nature and find out what the best result is. It follows the theory of hit and trial method. The agent is rewarded for a point with a correct Or incorrect answer, and on the basis of good reward points earn the model trains themselves and once trained it is ready to predict the new data that are being introduced to it. Keintorce learning is very diverse compared to supervised and supervised learning.
Where we can easily see the relationship between supervised and unsupervised (presence Or absence of labels), relationships in strengthening teaching are less positive. Some people try to tie the knot of reading close to these by describing them as a type of readıng at relies on time-based label sequences, however, my view is that that just makes things very confusing.
I prefer to look at strengthening reinforcement as learning from mistakes, Fit the reinforcement leaming algorithm in any environment and it will make many mistakes in the beginning.
As long as we provide a specific type of signal in an algorithm that combines positive behaviour with positive signals as well as negative and negative behaviours, we can strengthen our algorithm to select positive behaviours rather than have ones. Over time, our learning algorithm learns to make smaller mistakes than before.
The strengthening of learning is largely driven by morality. It has influences from the held of neuroscience and psychology, However, to really understand the of reading, let’s separate the concrete example, Let’s take a look at teaching an agent to play the game Mario.
For any reinforcement learning problem, we need an agent and a location and a way to connect the two items using a feedback loop. To connect the agent to the environment, we give you a set of actions that you can take that affect the environment.
To connect the environment to the agent, we are able to continuously extract two signals from the agent:
An update state and a reward (our signal to strengthen the behaviour). In Mario’s game, our agent is our learning algorithm and our environment is a game. Our agent has a set of actions.
These will be our buttons. Our updated status will be for each frame of the game as time goes on and our reward signal will be a change in points. As long as we connect all of these things together, we will have established a strong sense of learning to play the game Mario.
What is User Logging?
A little user experience, but still very effective, we can use unchecked reading to collect logs and user problems. This can help companies identify key themes in the problems their customers face and address these issues, by improving product or designing FAQ to address common issues. In any case.
What is Supervised Learning?
Supervised Learning, where you might think the learning is guided by a teacher. We have a dataset that works as a teacher and its role is to train a model or machine. When a training model can begin to make predictions or decisions when given new data.
In Conclusion-
The main difference between Regression and Classification algorithms is that Classification algorithm is used to predict the discrete values such as Male or Female, True or False, Spam or Not Spam, etc. The model learns by observing and discovering properties in data. When a model is given a database, it automatically detects patterns and relationships in the database by creating clusters in it. Classification is the process of finding a function that helps to classify the database into categories based on different parameters.
New Post





