
Artificial Intelligence (AI) is a rapidly evolving technology, made possible by the Internet, which can have a profound impact on our daily lives. Machine learning traditionally refers to the artificial creation of human-like intelligence that can read, discuss, organize, understand, or use natural language.
Types of machine learning algorithms :
Choosing the right algorithm is part of science and part of art. Two data scientists tasked with solving the same business challenge can select different algorithms to approach the same problem.
However, to understand the different classes of machine learning algorithms help data scientists identify the best types of algorithms. This section gives you a brief overview of the main type’s machine learning algorithms.
Bayesian:
Bavesian algorithms allow data scientists to record earlier beliefs as to which models ls look like, they are not independent of that data he says. With too much focus on model defining data, you might he wonders why people might be interested in Bavesian this.
These algorithms are especially useful if you do not have much data values to algodenty model. The Bayesian algorithm will make sense,
for example, if you information on a particular part of the model can therefore have one previous have of take the issue of medical imaging diagnosis a system that monitors lung encode disorders.
When a magazine study is published balances the risk of various lung problems based on lifestyle, those possibilities can be modelled.
Clustering:
together is an easy way to understand – objects with the same parameters are grouped together (in groups). All items in the collection are very similar items in other collections.
Clustering of the unattended type read because the data has no label. The algorithm translates the parameters form each object and then combine it accordingly.
See on twitter like and share.
Decision tree:
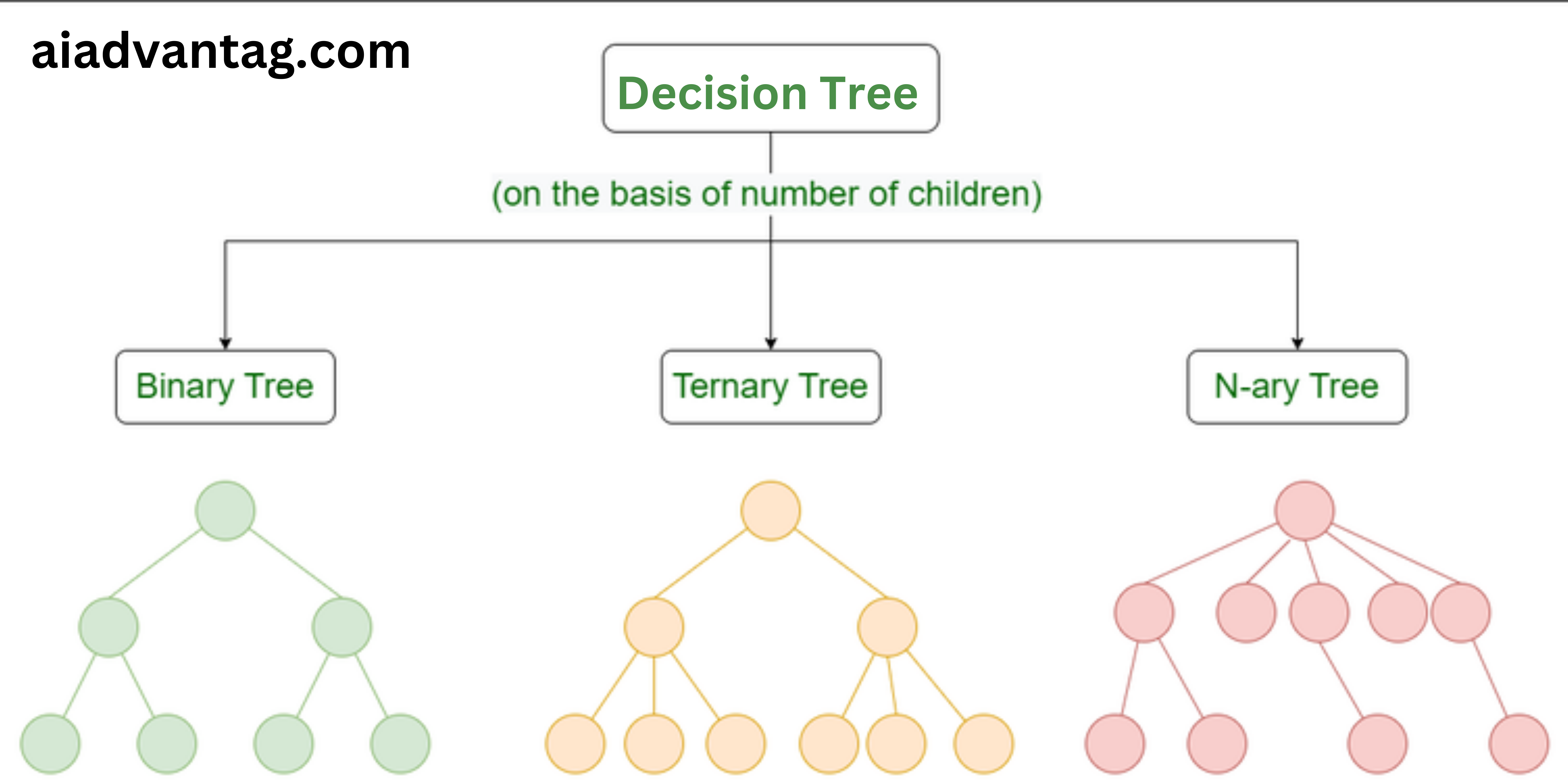
Decision tree algorithms use branch structure to illustrate the consequences of the
decision. Decision trees can be used to draw possible drawings the consequences of the given to nodes based on chances of an outcome occurring. Decision trees are sometimes for advertising campaigns. You may want to predict the effect of sending customers expects a 50% coupon.
You can split customers into four parts: Motivators who will buy when they gain access. Guaranteed items to buy anyway. Lost causes that can never be bought.
Soft customers may react negatively to outreach effort.
If you are posting a marketing campaign, you obviously want to avoid it to send items to three groups because you will not answer, buy anyway, or actually respond negatively.
Directing believers will give you the best return on investment (ROI). The decision tree will help you to draw maps of these four groups and set expectations with customers depending on who will respond excellent for marketing campaigns.
Dimensionality reduction:
Reducing size helps systems delete incorrect data is useful for analysis. This group of algorithms is used for deletion unwanted data, outliers, and other unusable data.
Size reduction can be helpful when analyzing data from sensors and other Internet of Things (lot) use cases. In IoT systems, there it could be thousands of data points that just tell you that sensor is on. Storing and analyzing that “on” data is useless and will take up Significant storage space.
Moreover, by removing this unwanted data, machine learning performance the system will improve. Eventually, reducing size will also do help analysts visualize data.
Instance based:
Instance-based algorithms are used when you want to categorize new data points are based on the similarity of the training data. This is set algorithms are sometimes called lazy students because there is no training phase.
Instead, algorithms are based on the model simply associate new data with training data and separate new ones data points are on similarity to training data.
Occasional support is not well suited to the data sets contains random variables, invalid data, or data with missing values. Periodically based algorithms can be very helpful in identifying a pattern.
For example, learning for example is applied to chemicals as well biological structural analysis and spatial analysis Analysis in fields of biology, medicine, chemistry and engineering usually uses various algorithm.
Neural networks and deep learning:
The neural network attempts to mimic the way the human brain reacts to problems and utilizes layers of interconnected units to read and provide relationships based on visual information. The neural network can have several layers connected.
When there is more network types are able to adapt and learn as data changes. Neural networks are often used when data is unlabelled or unorganized.
One of the most important aspects of the use of neural networks is computer vision. In-depth learning is linked today in a variety forms. Self-driving cars use in-depth learning to help the car understand the environment around the car.
As cameras take pictures of natural surroundings, in-depth learning algorithms translate random data to help the system make decisions that are closer to early time. Similarly, in-depth study is included in applications used by radiologists to help interpret medical imaging.
Figure: shows the formation of a neural network. Each layer of neural network filters and change details before passing it will be in the next layer.
Linear regression:
Regression algorithms are widely used in mathematical analysis and are important algorithms used in machine learning. Postponement algorithms help analysts to show relationships between data points.
Regression algorithms can measure the strength of a combination between variables in the data set. In addition, regression analysis can be 1seful in predicting future data rates based on history prices.
However, it is important to remember the retreat analysis assumes that the merger is related to contention. Apart to understand the context around the data, regression analysis is possible lead you to inaccurate predictions
Regularization to avoid over-fitting:
Design is a way to change models to avoid a problem excessive skipping. You can add storm to any machine learning model.
For example, you can postpone a decision tree del. The redesign makes the models extremely difficult to they tend to be extreme.
If the model does not exceed, it will give the wrong one predictions when new data sets are use. Excess occurs when the model is designed for specific data set but will have less generalized predictive power data set.
Rule-based machine learning:
Law-based learning algorithms use the rules of relationships to describe data. The legal system can be compared to machine learning programs that form a possible model often applied to all incoming data.
In abstract, it is based on rules the systems are easy to understand: When entering X data, do Y. However, as programs begin to be implemented, it is based on rules the machine learning process can be very complicated.
Or example, the system could include 100 pre-defined rules. AS the system meets additional data and is trained, it is possible that there may be hundreds of exemptions from the laws.
Icon it is important to be careful when creating a code based on those rules it does not become so complex that it loses its appearances. Imagine how difficult it would be to create a law-abiding law algorithm to use tax code.
Processes of machine learning systems:
Through the repeated process of developing and refining the model, selecting the appropriate algorithm, training, and system testing start. Training is a critical step in the process of machine learning.
When you train a machine learning program, you know input (eg. customer income, purchase history, location, etc.), and you know your desired goal (predicting the customer output tendency).
However, the lesser known is the mathematical operations to convert that raw data into a customer prediction of chrome.
As the learning algorithm is presented to get more and more customer data, the system will be bigger accurate in predicting customer potential.
Training a machine learning algorithm to create an accurate the model can be divided into three steps :
1. Representation:
The algorithm creates a model for converting embedded data to the results you want. As the learning algorithm is presented for more information, it will begin to study the relationship between raw data and what data points are powerful predictors of the result you want.
2. Testing:
As the algorithm creates multiple models, it can be human or the algorithm will need to test and evaluate the models depending on the model that produces the most accurate predictions.
It is important to remember that behind the model is active, will be disclosed in unknown details. Like result, make sure the model is made differently and does not overwork your training data.
After the algorithm created and acquired many models, choose the most efficient algorithm. As you expose the file algorithm for various sets of input data, select the most Standard model.
The most important part of the training process is getting enough data to be in a position to test your model. Usually the first one passing in training provides mixed results. This means you may need to refine your model or provide more data.
Machine learning cycle :
Creating a machine learning program or using a machine learning algorithm is a repetitive process. You can’t simply train the model once and leave it alone – data changes.
changing preferences, and competitors will appear. Therefore, you need to keep your model fresh when it comes to production. While you will not need to do the same level of training that you needed when you were building the model, you would not think it would be independent.
The machine learning cycle continues, and choosing the right machine learning algorithm is one of the steps. The steps of the machine learning cycle are as get details the right sources of data is the first step in the cycle.
In addition, as you develop your machine learning algorithm, consider expanding the targeted data to improve the system.
Organize data: Make sure your data is clean, secure and controlled. If you perform a wrong machine learning program based on incorrect data, the application will fail. Choose a machine learning algorithm: You can have many machine learning algorithms that work on your data and business challenge.
Train: You need to train the algorithm to create a model. Depending on the type of data and algorithm, the training process can be monitored, supervised or taught reinforcement.
Analyze: Rate your models to find the most effective algorithm.
Use: Machine learning algorithms create models that can be used in both cloud and local applications.
Predictability: After deployment, start making predictions based on new incoming data.
Check predictions:
Check the accuracy of your predictions. The information you collect from analyzing the accuracy of the predictions and then returned to the machine learning cycle to help improve accuracy.





