
A business Analysis Framework for Data Warehouse Design . The business analyst get the information from the data warehouses to measure win performance and make critical adjustments in order to win over other business holders in the market.
Data warehouse offers the following advantages:
- it can enhance business productivity as gathering information quickly and efficiently it helps us manage customer relationship by a consistent view of customers and items it helps in bringing down the costs by tracking trends and patterns over a long period in a consistent and reliable manner.
- To design an effective data warehouse we need to understand and analyze business needs and construct a business analysis framework.
- Building and using a data warehouse requires business skills, technology skills, and program management skills.
- Each person has different views regarding the design of a data warehouse. These views are as follows.
- The top-down view: allows the selection of relevant information desirable for a data warehouse which matches current and future business needs data warehouses.
- The operational system presents the information being captured, stored, and managed, which may be documented at various levels of detail and accuracy, from individual data source tables to integrated data source tables.
- The data warehouse view: includes the fact tables and dimension tables which represents the information stored inside the data warehouse as well as the information regarding the source, date and time of origin for providing historical context.
Data warehouse design process :
Top-down approach, a bottom-up approach, or The top-down approach starts with the overall design and planning. It is useful in the cases where the technology is mature and well known and the business problem is clear The bottom-up approach starts with experiments and prototypes.

This is useful in the early stage of business modeling and technology development. It allows an organization to move forward at considerably less expense and to evaluate the technological benefits before making significant commitments.
In the combined approach, an organization can exploit the planned and strategic nature of the top-down approach while retaining the rapid implementation and opportunistic application of the bottom-up approach.
From the software engineering point of view, the design and construction of a data warehouse may consist of the following steps: planning, requirements study, problem analysis, warehouse design, data integration and testing, and finally deployment of the data warehouse.
Large software systems can be developed using one of two methodologies: the waterfall method or the spiral method. The waterfall method performs a structured and systematic analysis at each step before proceeding to the next,
which is like a waterfall, falling from one step to the next. The spiral method involves the rapid generation of increasingly functional systems, with short intervals between successive releases.
This is considered a good choice for data warehouse development, especially for data marts, because the turnaround time is short, modifications can be done quickly, and new designs and technologies can be adapted in a timely manner.
In general, the warehouse design process consists of the following steps: Choose a business process to model orders, invoices, shipments, inventory, administration, sales etc.
Follow a data warehouse model for organizational business process which encompasses multiple complex object collections. Choose a data mart model for departmental process which focuses on the analysis of a kind of business process.
Choose the business process grain, which is the fundamental, atomic level of data to be represented in the fact table for the data warehouse design process. For example. individual transactions, individual daily snapshots and so on.
Choose the dimensions that will apply to each fact table record. For example, time item, customer, supplier, transaction type, status etc. Choose the measures that will populate each fact table record. For example, name
additive quantities like rupees sold and units sold. Once a data warehouse is designed and constructed, the initial deployment of the warehouse includes initial installation, roll-out planning. training, and orientation. Platform upgrades and maintenance must also be considered.
Data warehouse administration includes data refreshment, data Source synchronization, planning for disaster recovery, managing access control and security, managing data growth, managing database performance, and data warehouse enhancement and
extension. Scope management includes controlling the number and range of queries, dimensions, and reports; limiting the data warehouse’s size or limiting the schedule, budget, or resources.
Various kinds of data warehouse design tools are available. Data warehouse development tools provide functions to define and edit metadata repository contents (e.g., schemas, script, or rules),
answer queries, output reports, and ship metadata to and from relational database system catelogs. Planning and analysis tools study the impact of schema changes and of refresh performance when changing refresh rates or time windows
Data Warehouse usage for Information Processing :
The data warehouse may be employed for knowledge discovery and strategic decision making using data mining tools.
- In this context, the tools for data warehousing can be categorized into access and retrieval tools, database reporting tools, data analysis tools, and data mining tools.
- Business users need know what exists in the data warehouse (through metadata), how to access the contents of the data warehouse, how to examine the contents using analysis tools, and how to present the results of such analysis.
- There are three kinds of data warehouse applications: information processing, analytical processing, and data mining.
- Information processing supports querying, basic statistical analysis, and reporting using crosstabs, tables, charts, or graphs. A current trend in data warehouse information processing is to construct low-cost web-based accessing tools that are then integrated with web browsers. Analytical processing supports basic OLAP operations, including slice-and-dice, drill- down, roll-up, and pivoting. It generally operates on historic data in both summarized and detailed forms. The major strength of OLAP over information processing is the multidimensional data analysis of data warehouse data. Data mining supports knowledge discovery by finding hidden patterns and associations, constructing analytical models, performing classification and prediction, and presenting the mining results using visualization tools.
From OLAP to Multidimensional data Mining :
Multidimensional data mining/exploratory multidimensional data mining/On Line Analytical Mining-OLAM integrates OLAP with data mining to uncover knowledge in multidimensional databases.
Among many different paradigms and architectures of data mining systems. multidimensional data mining is particularly important for the following reasons. High quality of data in data warehouses.
Most data mining tools need to work on integrated, consistent, and cleaned data, which requires costly data cleaning, data integration, and data transformation as preprocessing steps.
A data warehouse constructed by such preprocessing serves as a valuable source of high-quality data for OLAP as well as for data mining. Data mining may serve as a valuable tool for data cleaning and data integration as well.
Available information processing infrastructure surrounding data warehouses:
A systematic construction has comprehensively developed surrounding data warehouses, encompassing accessing, integrating, consolidating, and transforming multiple heterogeneous databases, ODBC/OLEDB connections, Web accessing and service facilities, and reporting and OLAP analysis tools.
It is practical to make the best use of the available infrastructures rather than constructing everything from scratch.
OLAP-based exploration of multidimensional data:
A user will often want to traverse through a database, select portions of relevant data, analyze them at different granularities, and present knowledge/results in different forms.
Multidimensional data mining provides facilities for mining on different subsets of data and at varying levels of abstraction-by drilling, pivoting, filtering, dicing, and slicing on a data cube and/or intermediate data mining results.
This, together with data/knowledge visualization tools, greatly enhances the power and flexibility of data mining
Users may not always know the specific kinds of knowledge they want to mine. By integrating OLAP with various data mining functions, multidimensional data minus provides users with the flexibility to select desired data mining functions and swap data mining tasks dynamically.
Multitier Architecture –
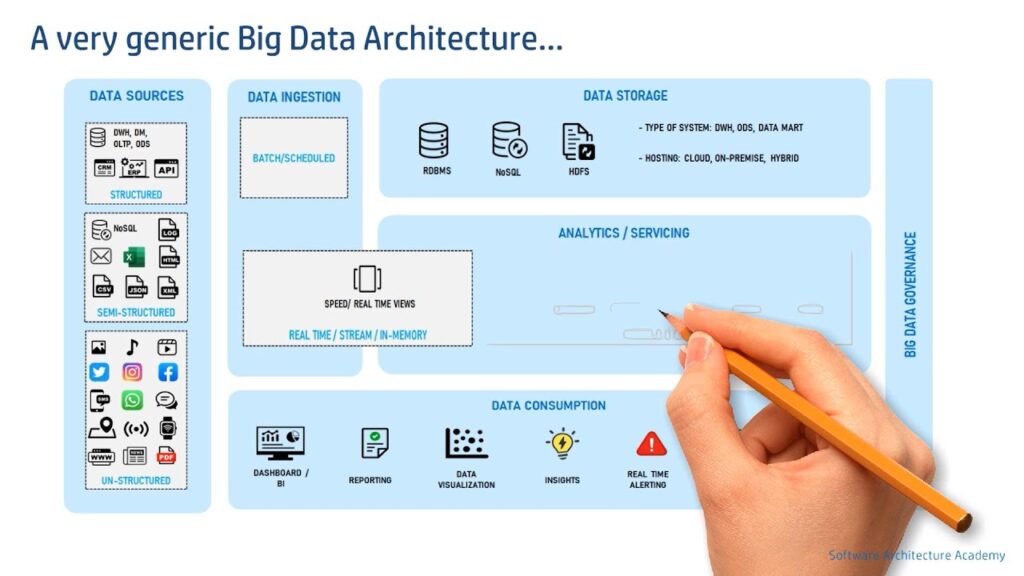
Design and construction of Data Warehouse:
To design an effective data warehouse, we need to understand and analyze business needs and construct a business analysis framework. Four different views regarding the design of a data warehouse are.
The top-down view: allows selection of the relevant information necessary for the data warehouse. The data source view: exposes the information being captured, stored, and managed by operational systems.
The data warehouse view: consists of fact tables and dimension tables. The business query view: sees the perspectives of data in the warehouse from the view of end-user
A Three-Tier Data Warehouse Architecture :
- Bottom tier is a warehouse database server
- Middle tier is a OLAP server
- Top tier is a front-end client layer
Bottom tier :
- A bottom-tier that consists of the Data Warehouse server, which is almost always an RDBMS.
- It may include several specialized data marts and a metadata repository.
- A Data Mart is a subset of a data warehouse in which a summarized or highly focused portion of the organization’s data is placed in separate database for a specific population of users. For example, A company might develop marketing & sales data marts to deal with customer information.
- Metadata repository is an integral part of a data warehouse system. It is a database created to store metadata. Metadata are data about data which can be categorized into business, technical or operational.
- When used in a data warehouse, metadata are the data that define warehouse objects. It should contain data warehouse structure, Operational metadata, algorithms used for summarization, Mapping from the operational environment to the data warehouse, Data related to system performance, Business metadata)
- We use the back end tools and utilities to feed data into the bottom tier. These back end tools and utilities perform the Extract (which typically gathers data from multiple, heterogeneous, and external sources), Clean (which detects errors in the data and rectifies them when possible), Transform (which converts data from legacy or host format to warehouse format)
- Load (which sorts, summarizes, consolidates, computes views, checks integrity, and builds indices and partitions), and Refresh (which propagates the updates from the data sources to the warehouse) functions.
- Data from operational databases and external sources (such as user profile data provided by external consultants) are extracted using application program inter called a gateway.
- A gateway is provided by the underlying DBMS and allows customer programs to generate SQL code to be executed at a server.
- Examples of gateways contain ODBC (Open Database Connection) and OLE-DB (Object Linking and Embedding for Databases) by Microsoft and JDBC (Java Database Connection).
Middle Tier :
- In the middle tier, we have the OLAP Server that can be implemented in either of the following ways.
- By Relational OLAP (ROLAP), which is an extended relational database management system? The ROLAP maps the operations on multidimensional data to standard relational operations.
- By Multidimensional OLAP (MOLAP) model, which directly implements the multidimensional data and operations?
- For a user, this application tier presents an abstracted view of the database. This layer also acts as a mediator between the end-user and the database.
Top Tier :
- This tier is the front-end client layer.
- Top tier is the tools and API that you connect and get data out from the data warehouse. This layer holds the query tools and reporting tools, analysis tools and data mining tools.
Data Warehouse Models:
From the perspective of data warehouse architecture, we have the following data warehouse models – Virtual Warehouse.
- Data mart
- Enterprise Warehouse
- Virtual Warehouse
Data mart :
- Data mart contains a subset of organization-wide data. This subset of data is valuable to specific groups of an organization.
- In other words, we can claim that data marts contain data specific to a particular group. For example, the marketing data mart may contain data related to items, customers, and sales. Data marts are confined to subjects.
- Points to remember about data marts- Window-based or Unix/Linux-based servers are used to implement data marts. They are implemented on low-cost servers. The implementation data mart cycles is measured in short periods of time, i.e., in weeks rather than months or years.
- The life cycle of a data mart may be complex in long run, if its planning and design are not organization-wide. Data marts are small in size.
- Data marts are customized by department. The source of a data mart is departmentally structured data warehouse. Data mart is flexible.
Enterprise Warehouse :
- An enterprise warehouse collects all the information and the subjects spanning an entire organization.
- It provides us enterprise-wide data integration. The data is integrated from operational systems and external information providers. This information can vary from a few gigabytes to hundreds of gigabytes, terabytes or beyond.
Virtual Warehouse :
- A virtual warehouse is known as the view over an operational data warehouse.
- It is easy to build a virtual warehouse.
- Building a virtual warehouse requires excess capacity on operational database servers.





